
This blog post primarily tracks the evolution of collision update optimization for the “Bark” physics engine.
About Bark
Bark is a small physics engine initially developed for the SAE Institute.
Goals
- Develop a C++ 17 physics engine using my own Math library.
- Enable the application of physical forces to objects.
- Implement trigger collisions.
- Implement physical collisions.
Update Optimisation
While I was developing Bark, I realized that updating all the objects was too slow and wanted to optimize my code. Below, you will find the evolution of the different versions.
Naive implementation
First implementation
The first implementation of my update was to check the collisions between all the objects in 2 loops
for (std::size_t i = 0; i < _colliders.size() - 1; ++i)
{
for (std::size_t j = 0; j < _colliders.size(); ++j)
{
// Check collision between _colliders[i] and _colliders[j]
}
}But I quickly noticed that the program started to lag severely as soon as I added a large number of objects.
Here is an example with 100 circles, 100 rectangles and 100 triangles.
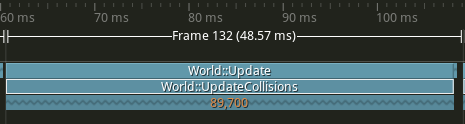
89'700 checks
We can see how slow and lagged it is
Second implementation
For the second implementation, I realized that I can reduce the number of collision checks by starting the second loop 1 element after the actual element and finishing it 1 element before, so I don’t have to check 2 times the same pair of elements and can remove some “if” statements
for (std::size_t i = 0; i < _colliders.size() - 1; ++i)
{
for (std::size_t j = i + 1; j < _colliders.size(); ++j)
{
// Check collision between _colliders[i] and _colliders[j]
}
}Here is the same example with 100 circles, 100 rectangles and 100 triangles.
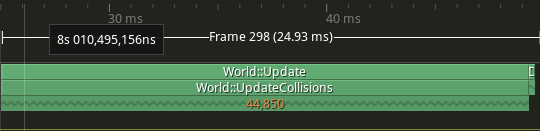
44'850 checks
A bit faster and fewer lags but still not good enough
QuadTree implementation
First implementation
I then decided that I want to reduce the number of useless collision checks even more, so I decided to implement a quad tree to separate the physical world in smaller areas and only do collision checks within the areas.
I did this by recursively inserting elements into the root node and when there is too many elements in a node, I split the node in 4.
Then, I check all possible collisions within the deepest layer of the quad tree.
I add elements to all the nodes they collide with and as I am using an unordered_set I don’t have to check if the pair of elements already exists.
if (node.Children[0] == nullptr)
{
for (std::size_t i = 0; i < node.ColliderRefAabbs.size() - 1; ++i)
{
auto& col1 = GetCollider(colRefAabb1.ColRef);
for (std::size_t j = i + 1; j < node.ColliderRefAabbs.size(); ++j)
{
// Check collision between node.ColliderRefAabbs[i] and node.ColliderRefAabbs[j]
}
}
else
{
for (const auto& child : node.Children)
{
UpdateQuadTreeCollisions(*child);
}
}We can now see it is already way better than the naive implementation.
Here is again the same example with 100 circles, 100 rectangles and 100 triangles.
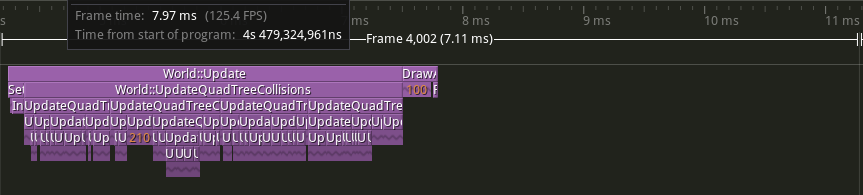
The collision update now takes only half the frame
We can see that it is way smoother
Some statistics
The tables below are a proof that the optimisation is real.
| Population | Mean (ms) | Median (ms) | Std dev (ms) |
|---|---|---|---|
| Normal update | 26.25 | 25.96 | 1.47 |
| Quad tree update | 0.093 | 0.032 | 0.271 |
Comparison of the update with and without the quad tree based on 200 frames
| P(T<=t) two-tail | t Critical two-tail |
|---|---|
| 1.10E-248 | 1.971603452 |
Student T-test using alpha at 5%
| Mean difference (ms) | Standard error (ms) | Margin of error (ms) | Minimal limit (ms) | Maximal limit (ms) |
|---|---|---|---|---|
| 26.535624 | 0.1162437836 | 0.2291866451 | 26.30643735 | 26.76481065 |
Here we can see that the minimal optimisation is about 26.3 ms
Second implementation
For the second implementation the goal was to reduce the number of memory allocations within the frame time.
To do so, instead of deleting and creating nodes at the start of the frame, I now use a vector of pre created nodes.

First implementation, at the start of the the frame, we see a huge spike of allocations/deallocations

Second implementation, the only allocations/deallocations left are those of the unordered_set
Thank you for reading so far !!!
I honestly hope, you enjoyed it :)